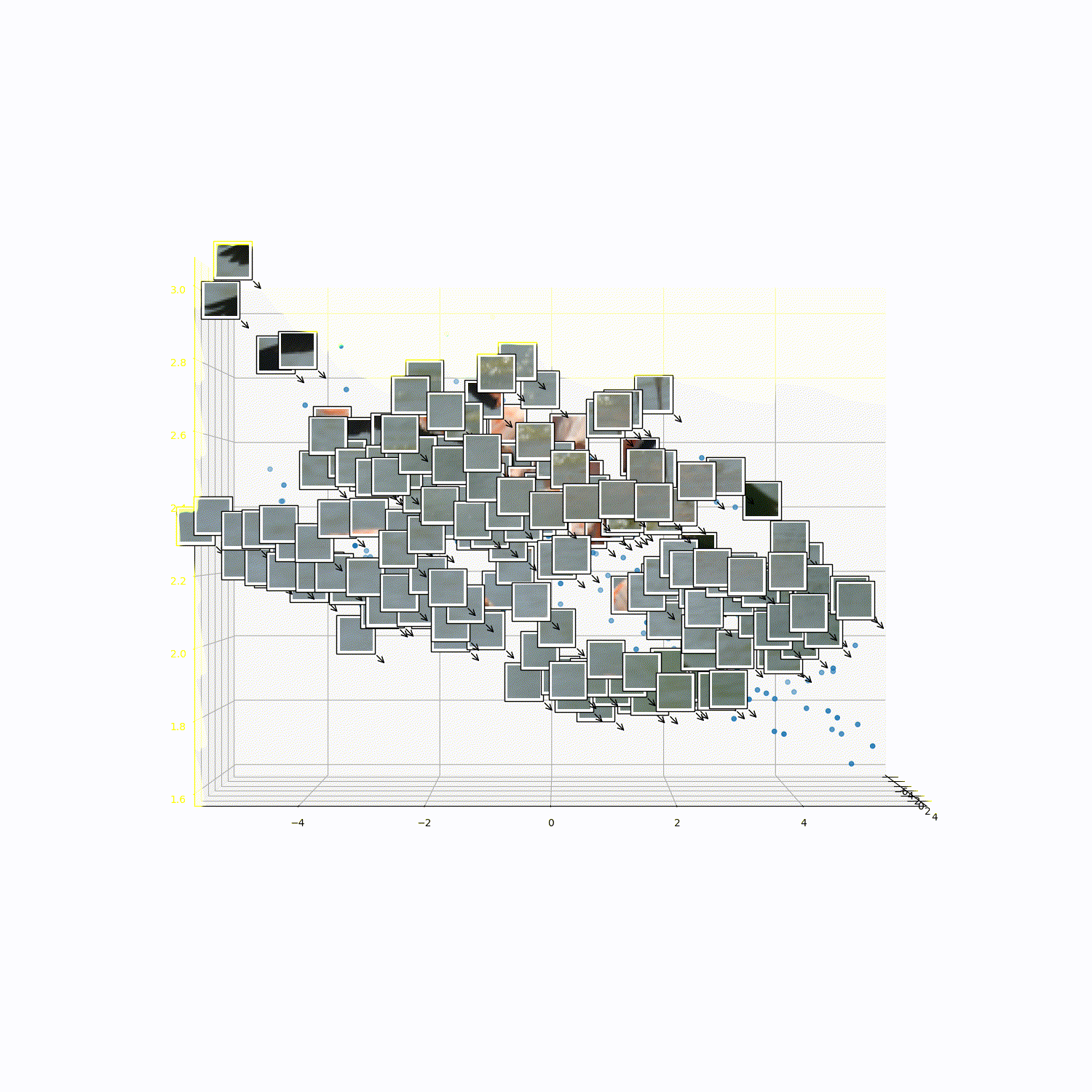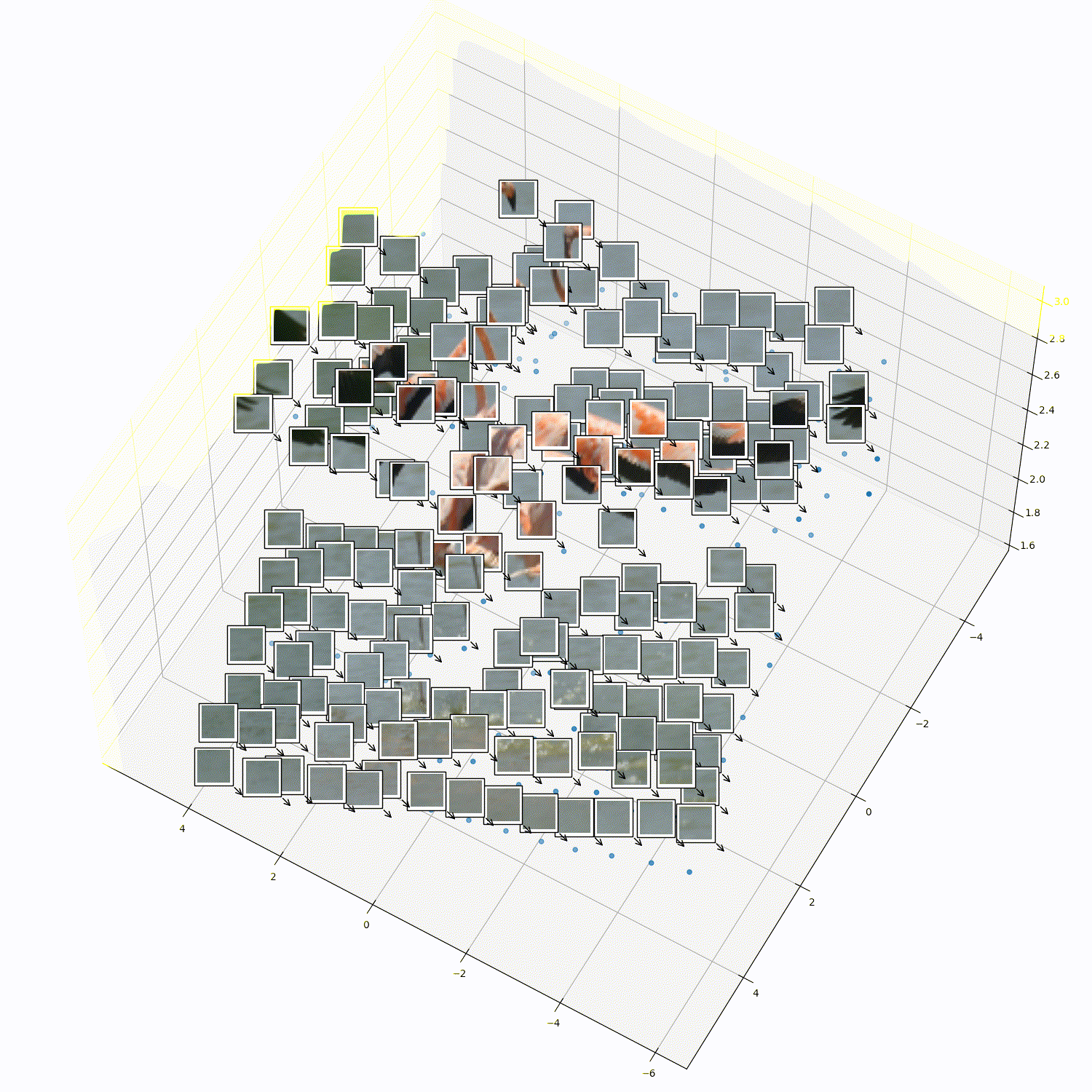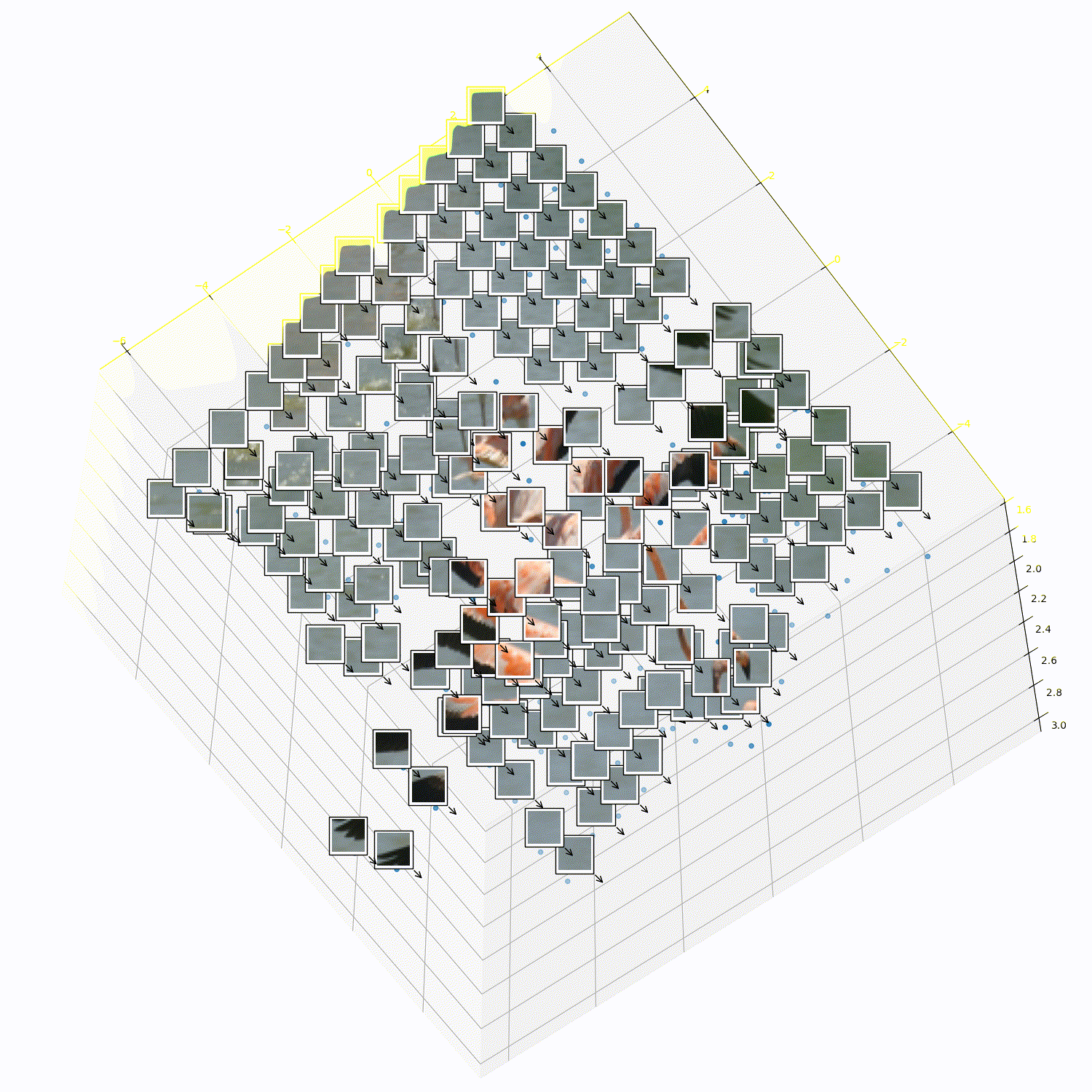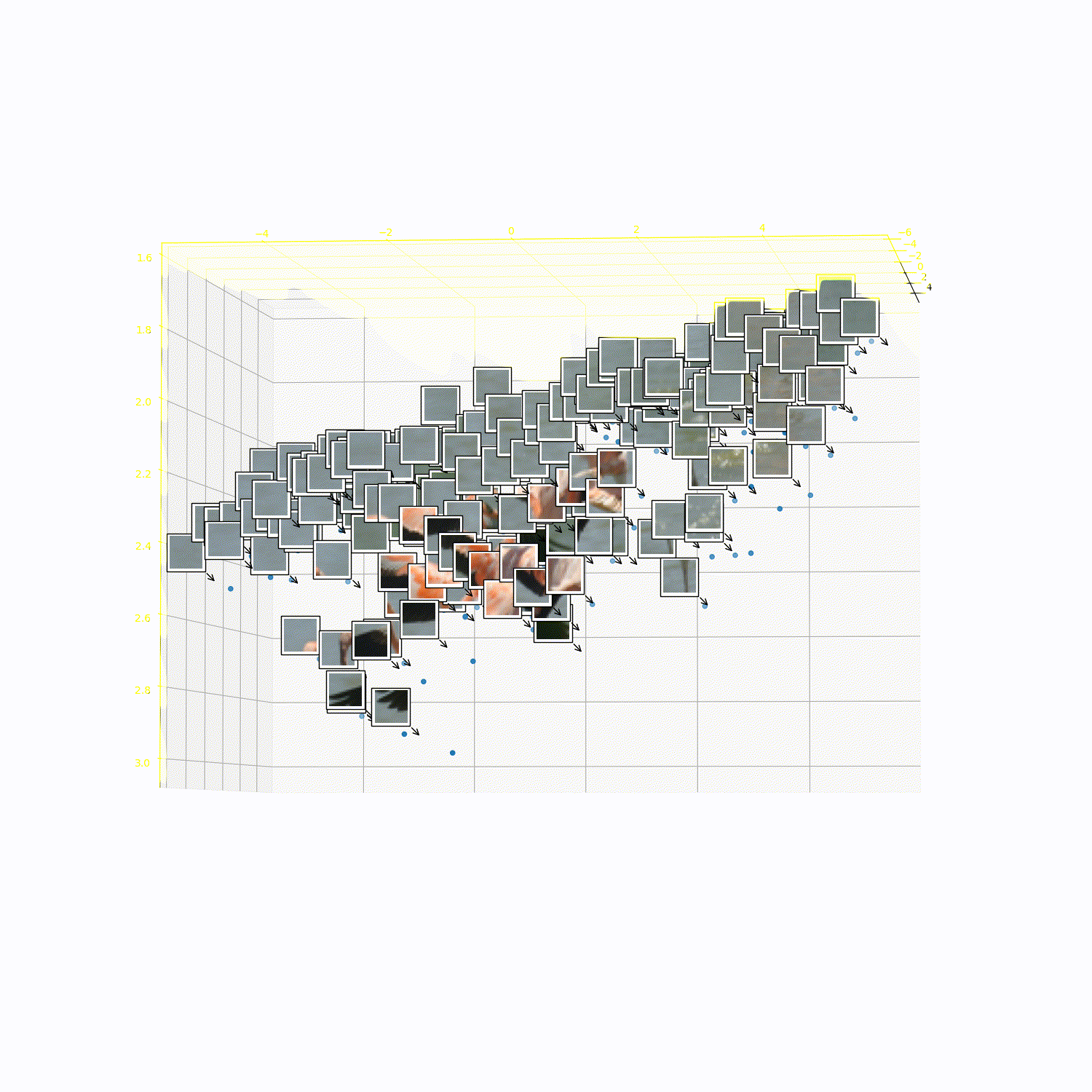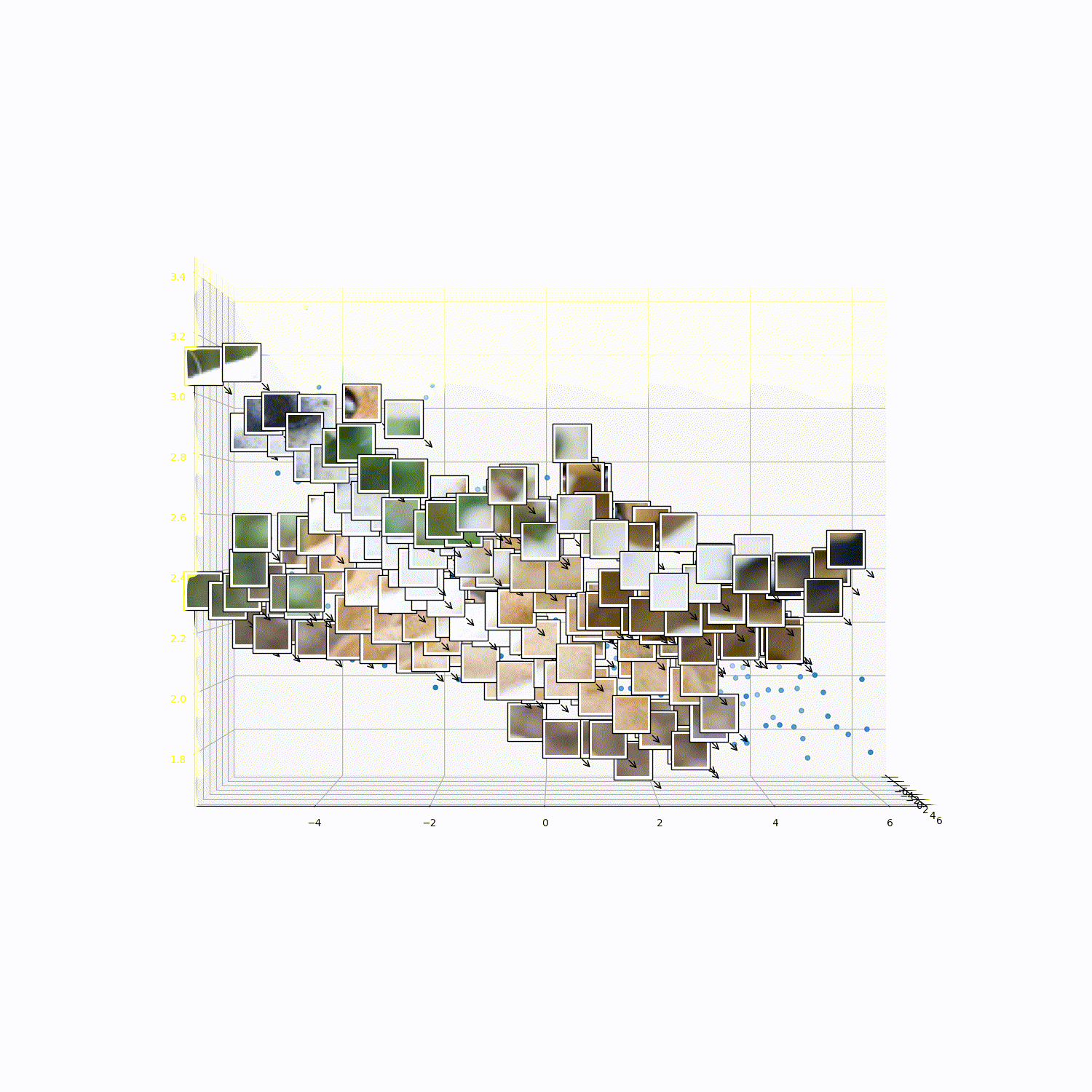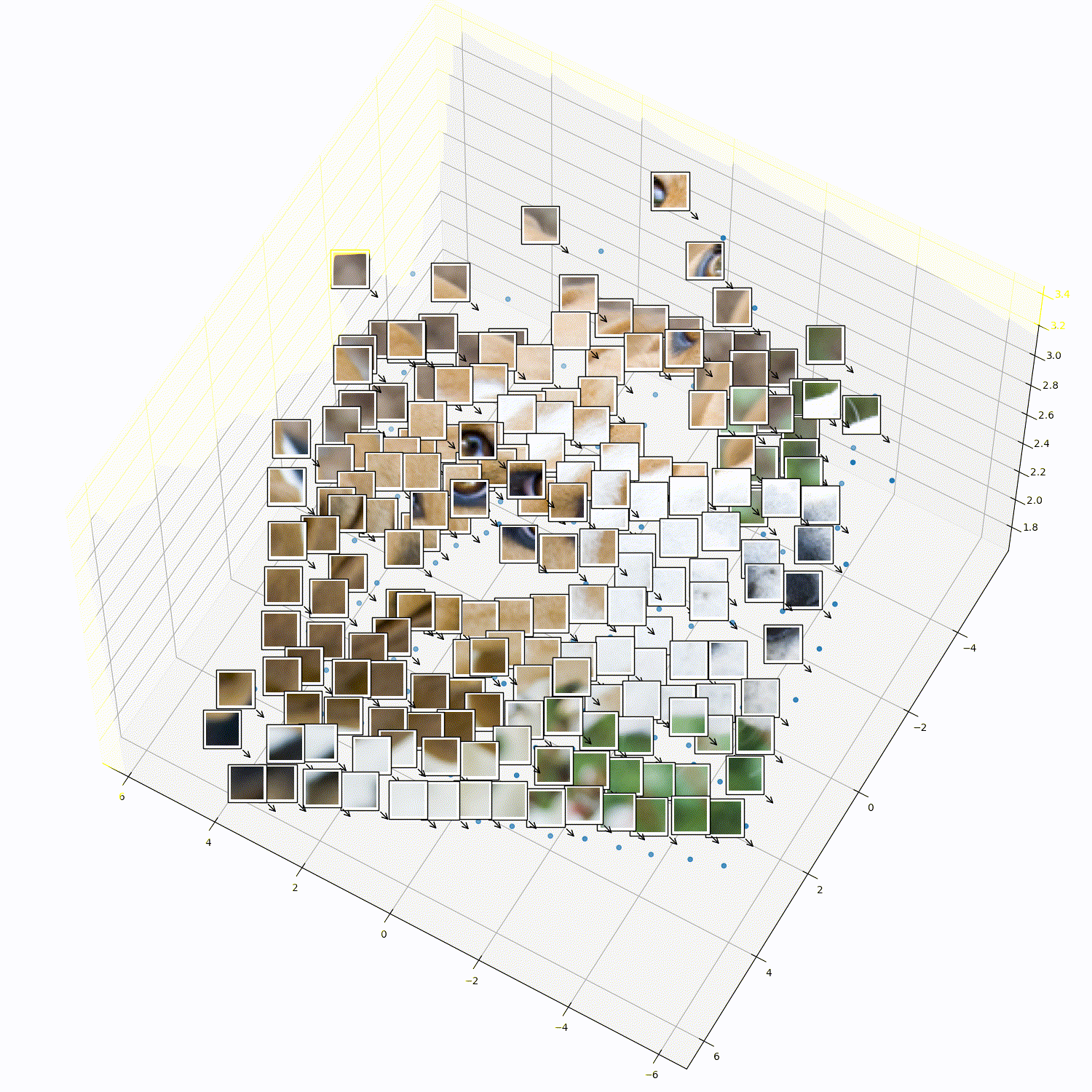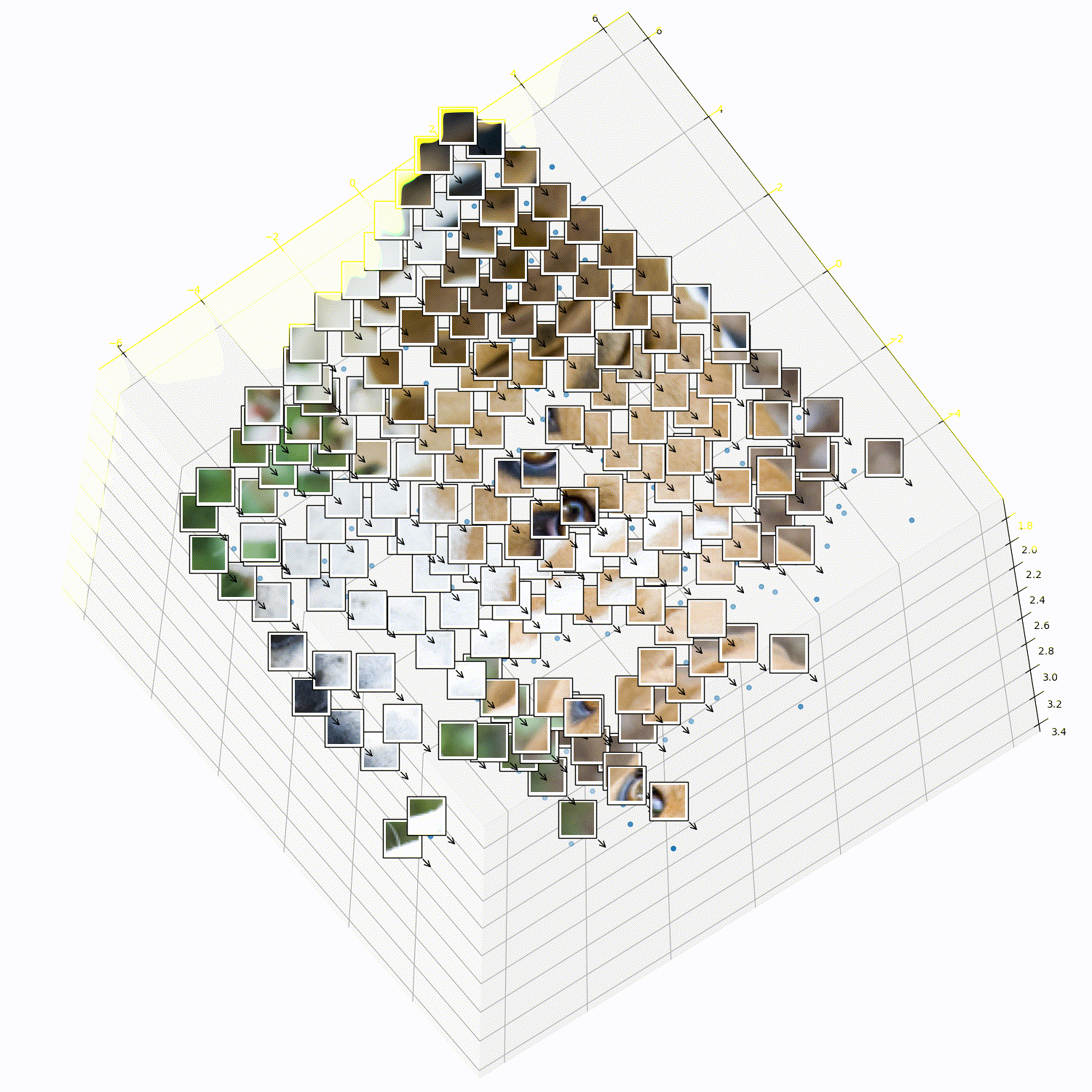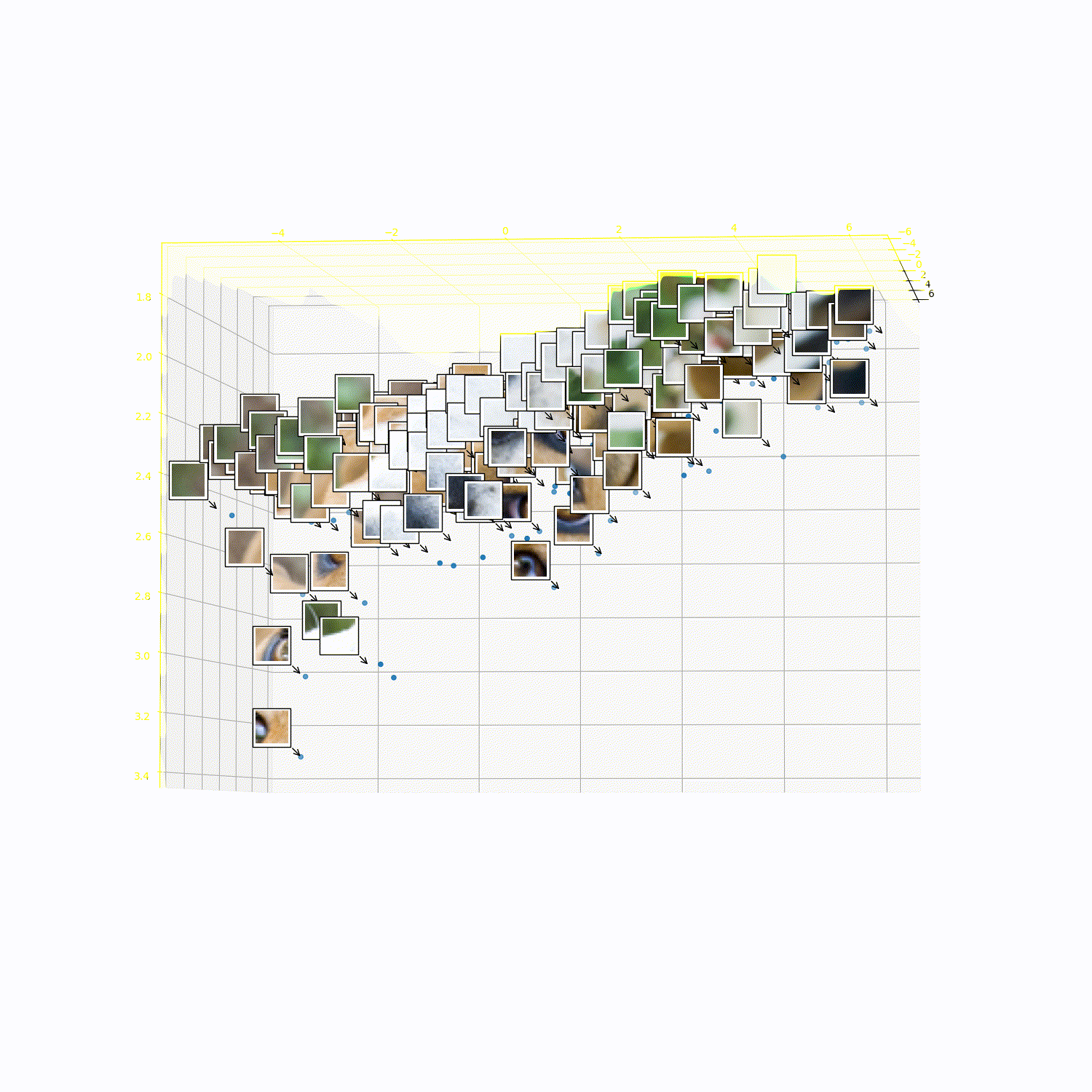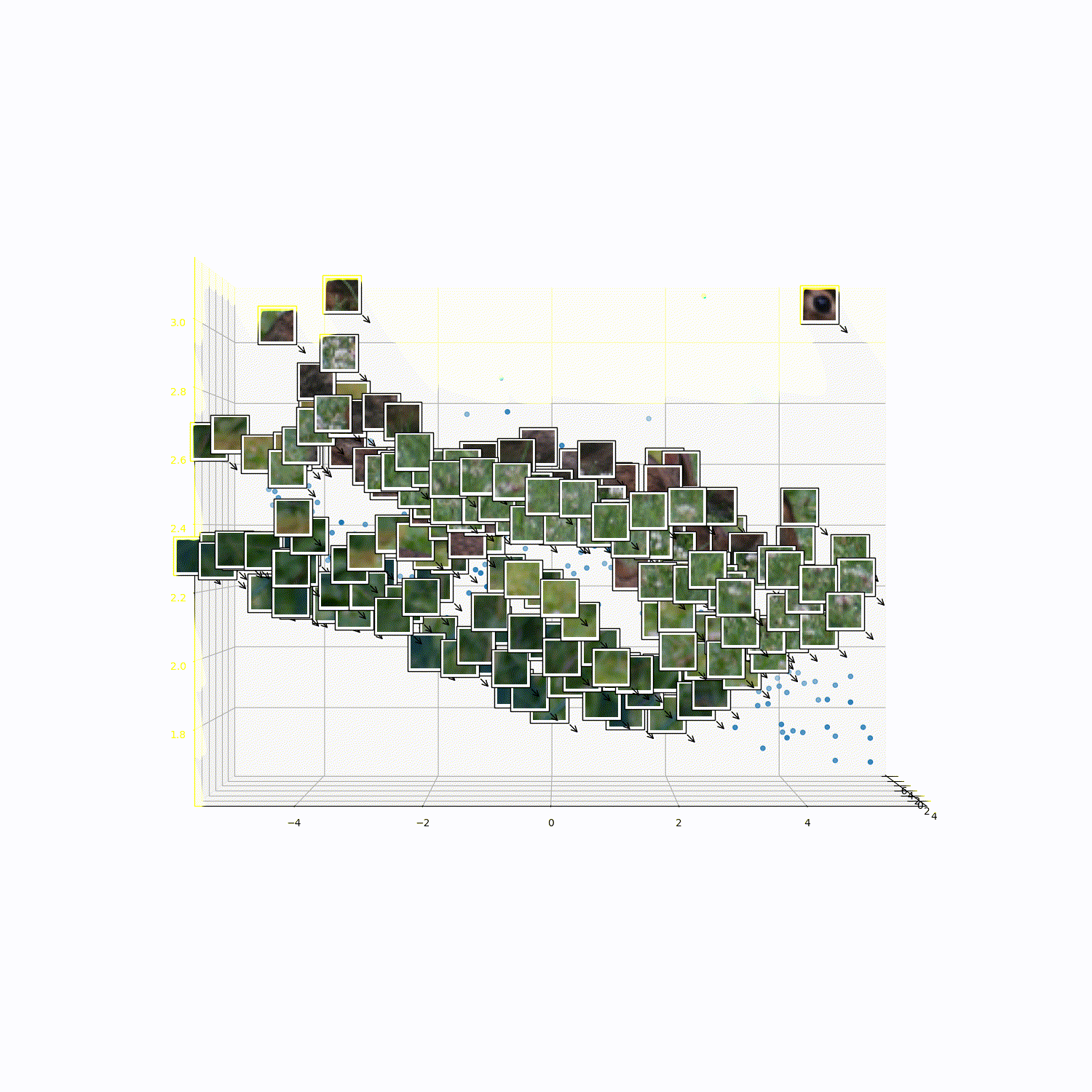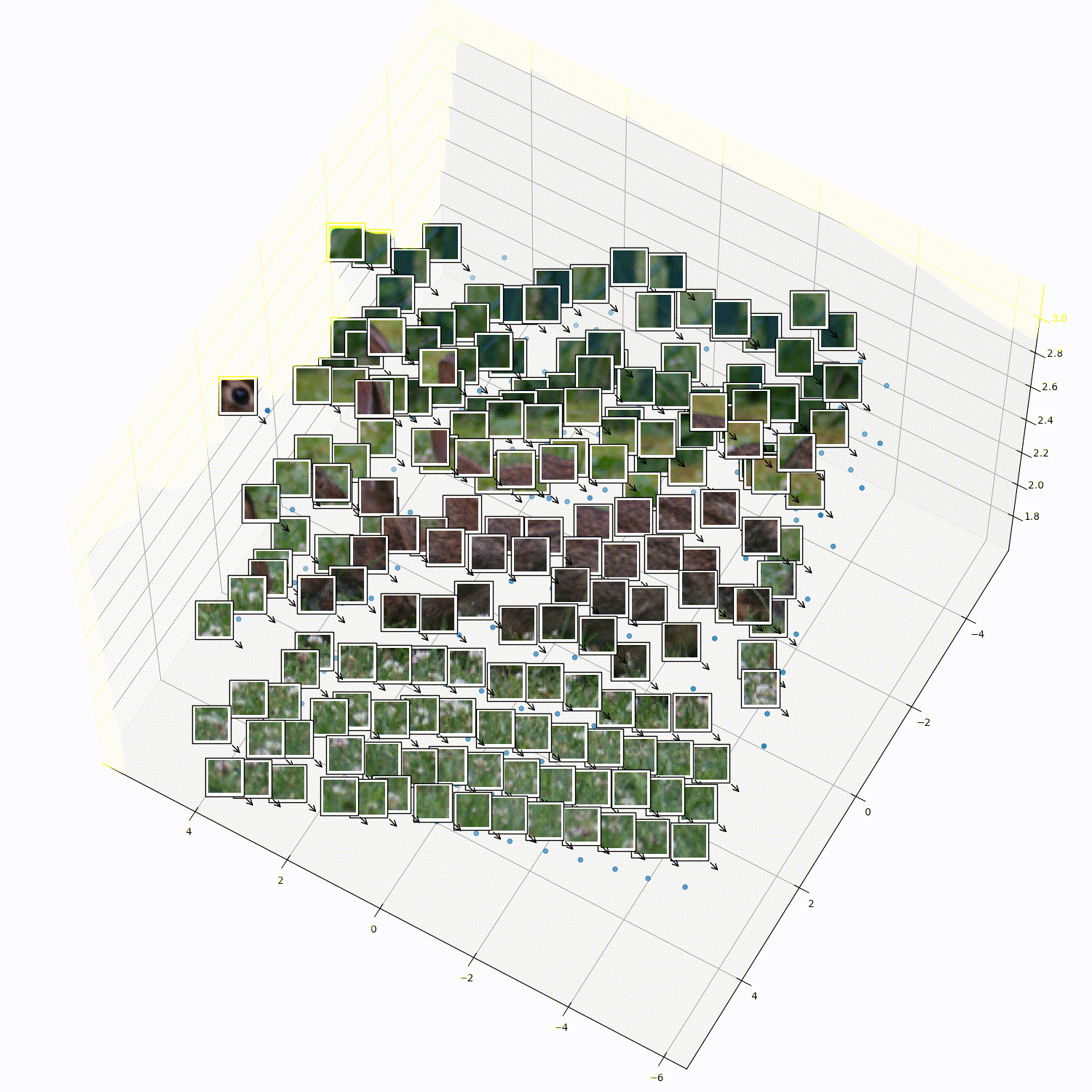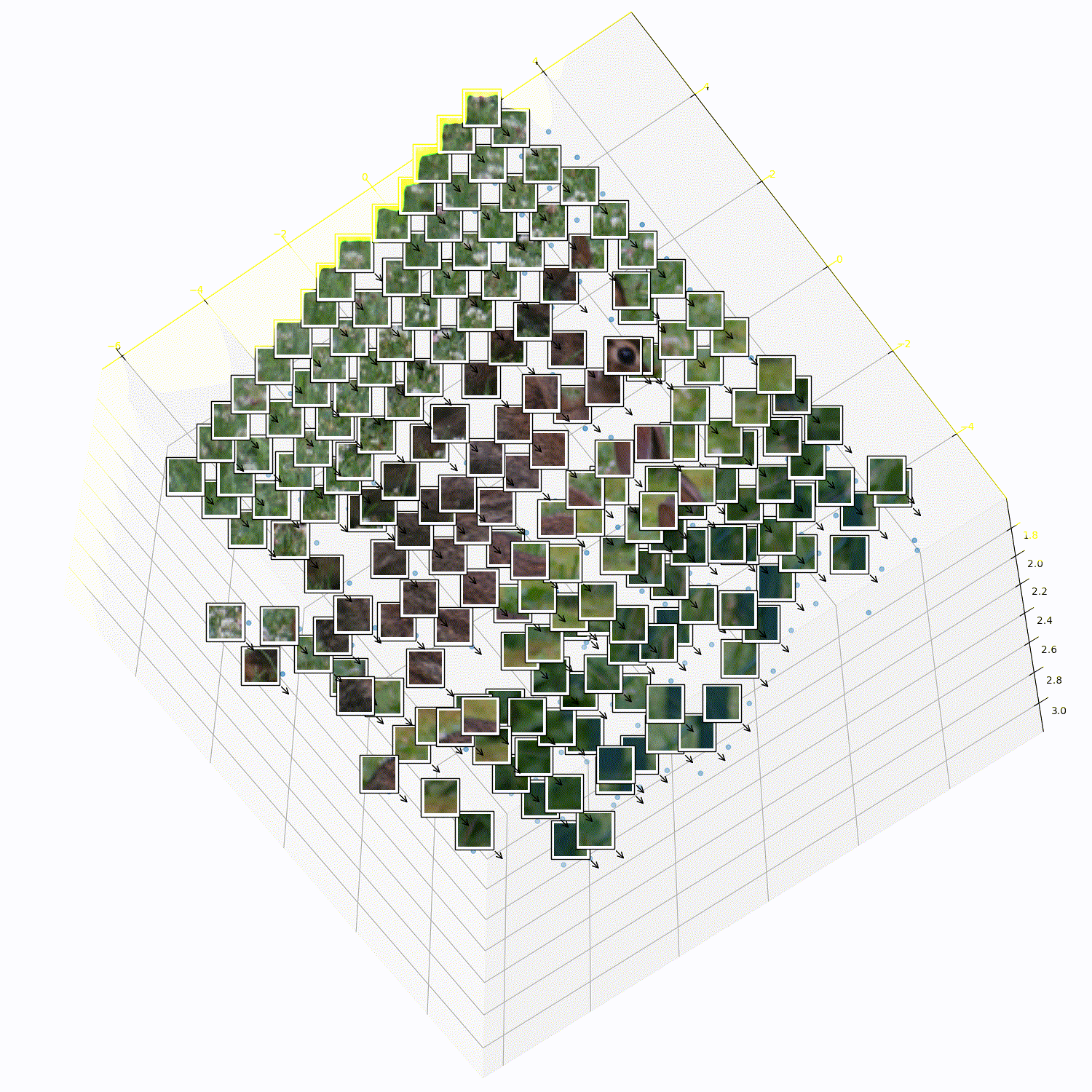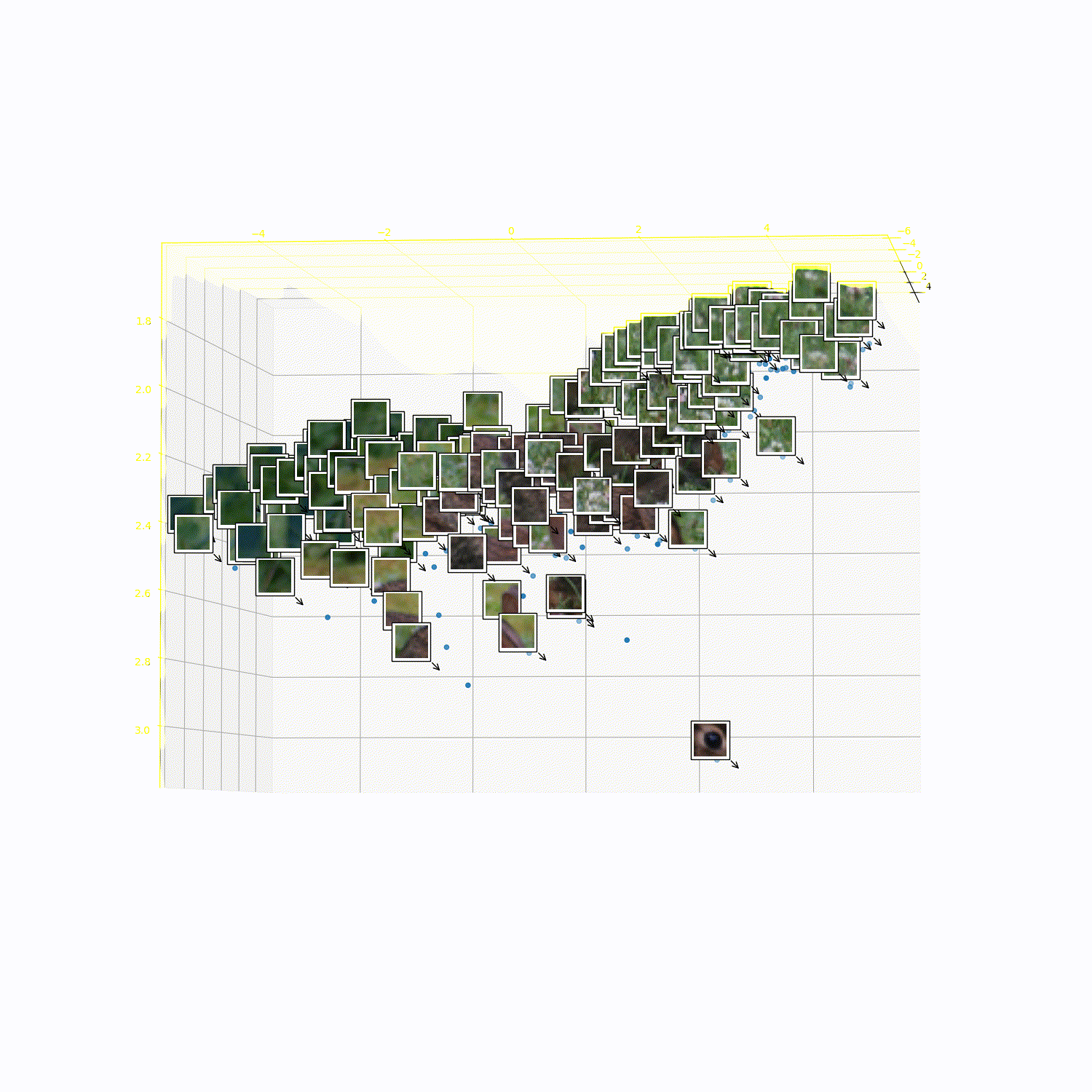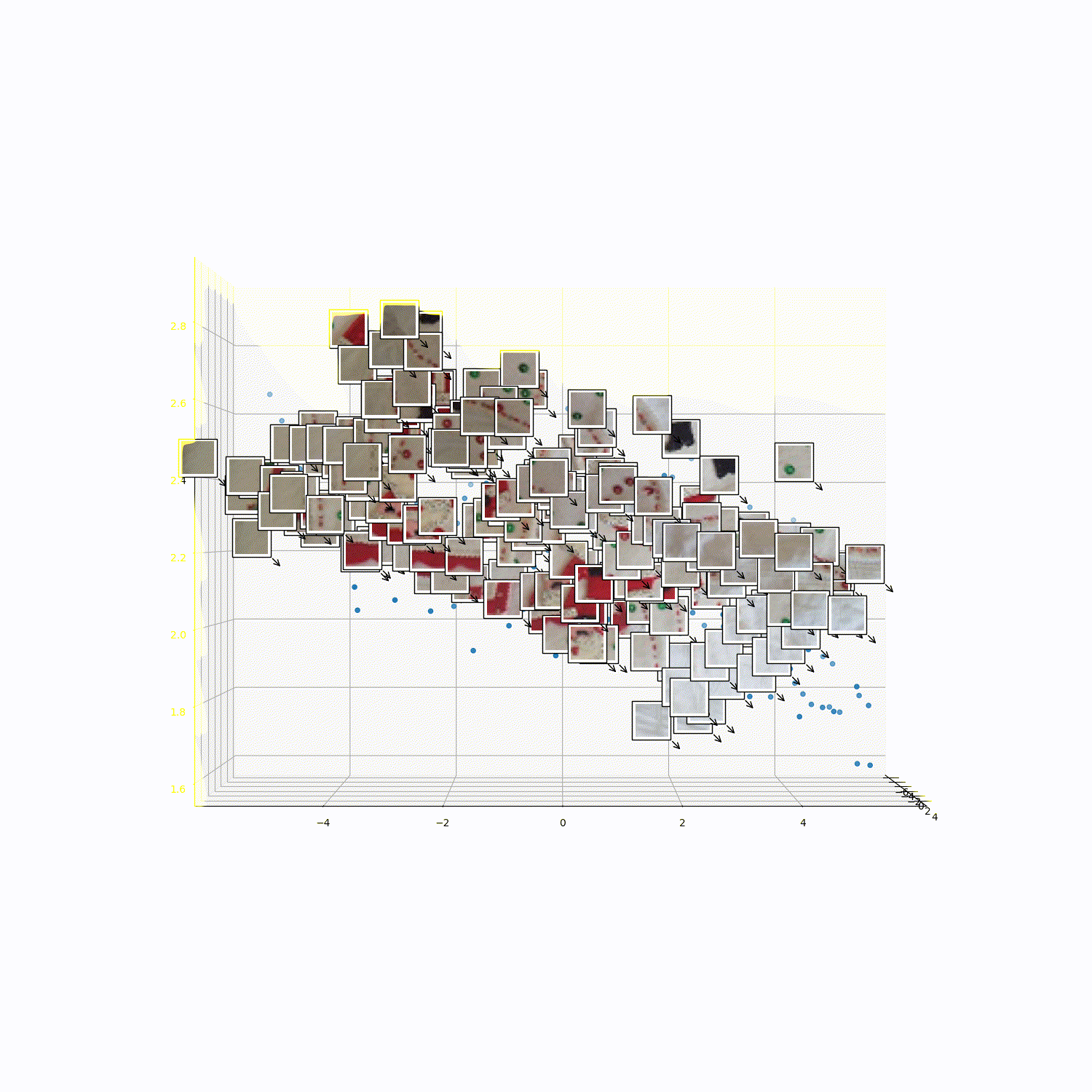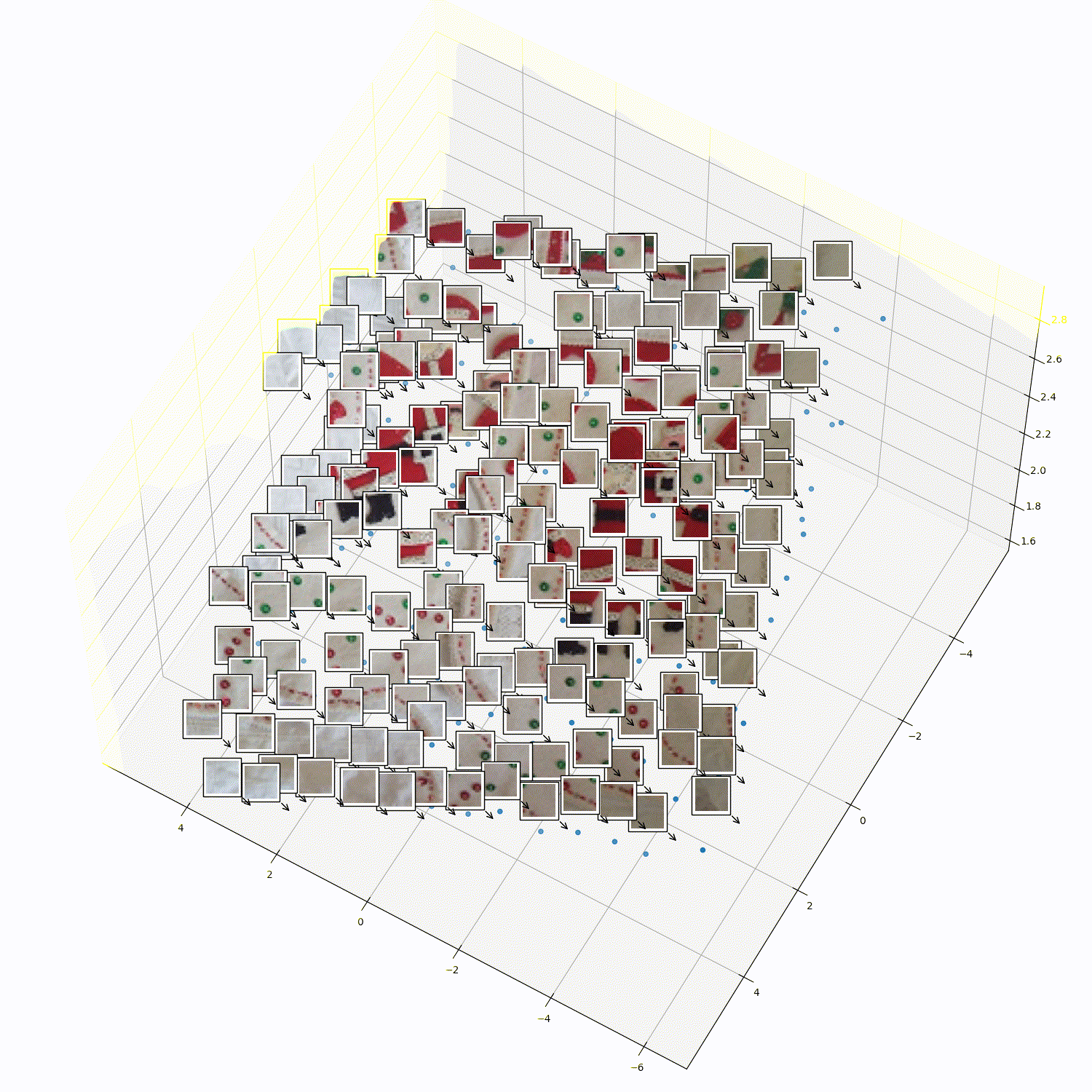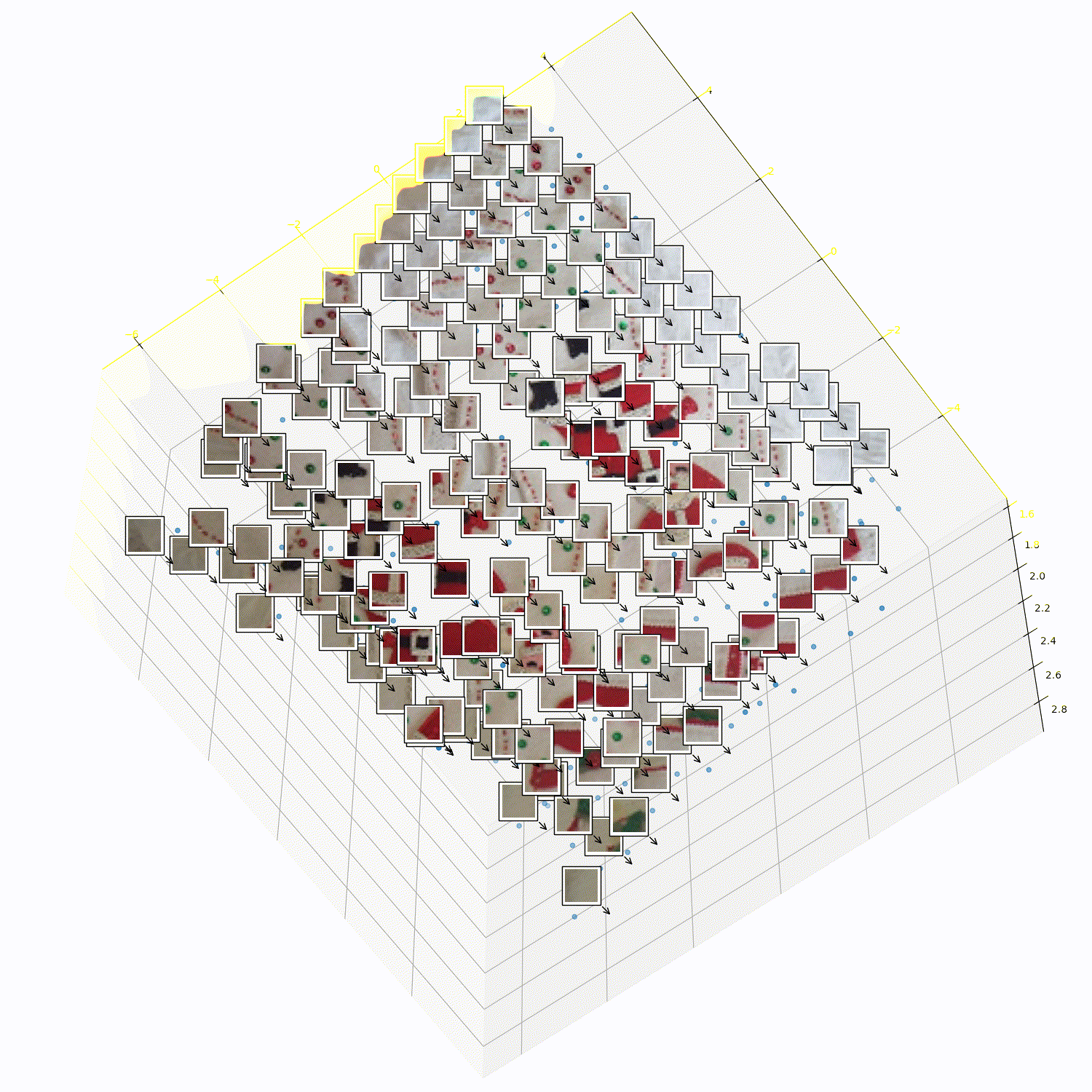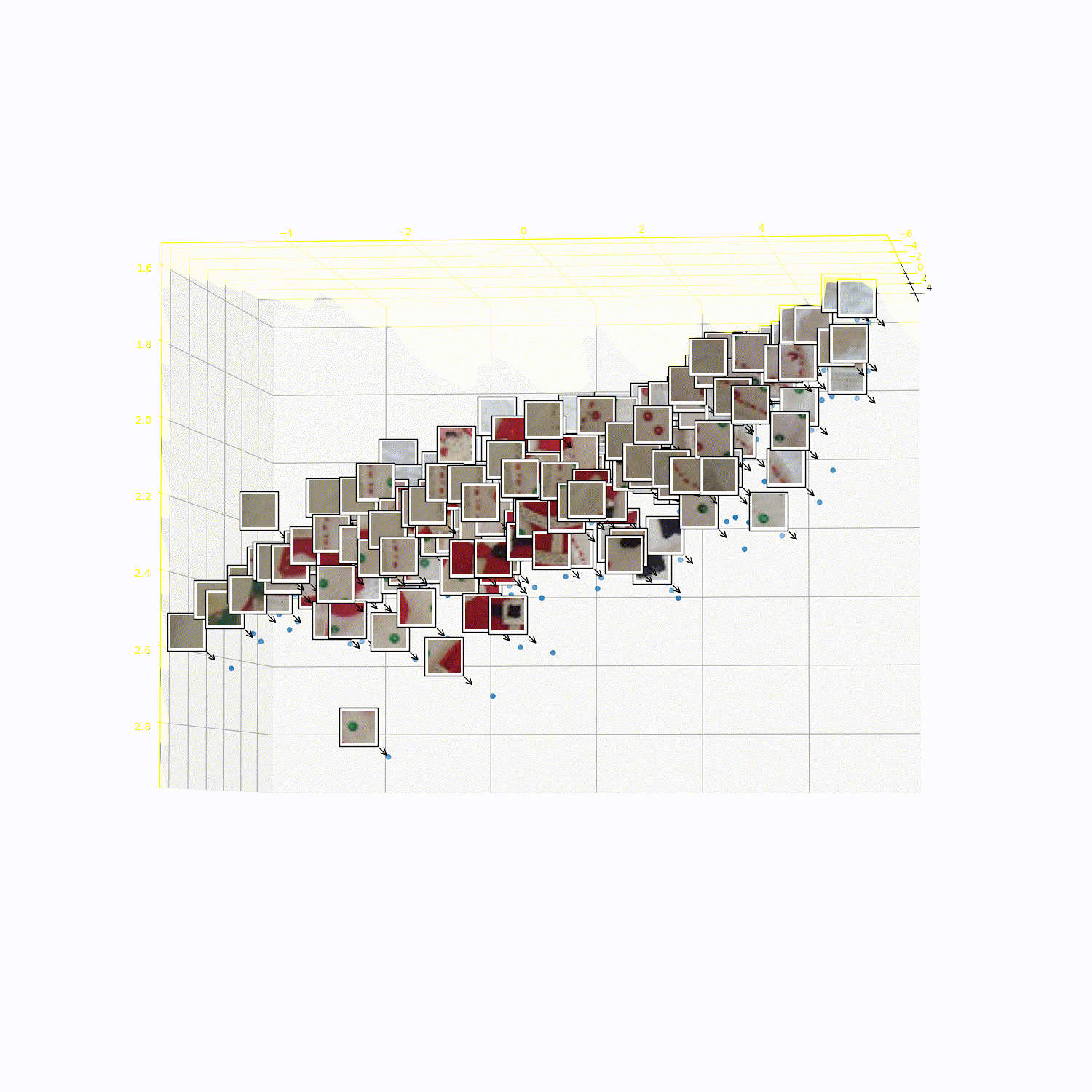Learning Viewpoint-Agnostic Visual Representations by Recovering Tokens in 3D Space
Jinghuan Shang1, Srijan Das1,2, Michael Ryoo1
1Stony Brook University 2UNC Charlotte
[arXiv][Code]
Abstract
Humans are remarkably flexible in understanding viewpoint changes due to visual cortex supporting the perception of 3D structure. In contrast, most of the computer vision models that learn visual representation from a pool of 2D images often fail to generalize over novel camera viewpoints. Recently, the vision architectures have shifted towards convolution-free architectures, visual Transformers, which operate on tokens derived from image patches. However, these Transformers do not perform explicit operations to learn viewpoint-agnostic representation for visual understanding, as in convolutions. To this end, we propose a 3D Token Representation Layer (3DTRL) that estimates the 3D positional information of the visual tokens and leverages it for learning viewpoint-agnostic representations. The key elements of 3DTRL include a pseudo-depth estimator and a learned camera matrix to impose geometric transformations on the tokens. These enable 3DTRL to recover the 3D positional information of the tokens from 2D patches. In practice, 3DTRL is easily plugged-in into a Transformer. Our experiments demonstrate the effectiveness of 3DTRL in many vision tasks including image classification, multi-view video alignment, and action recognition. The models with 3DTRL outperform their backbone Transformers in all the tasks with minimal added computation.

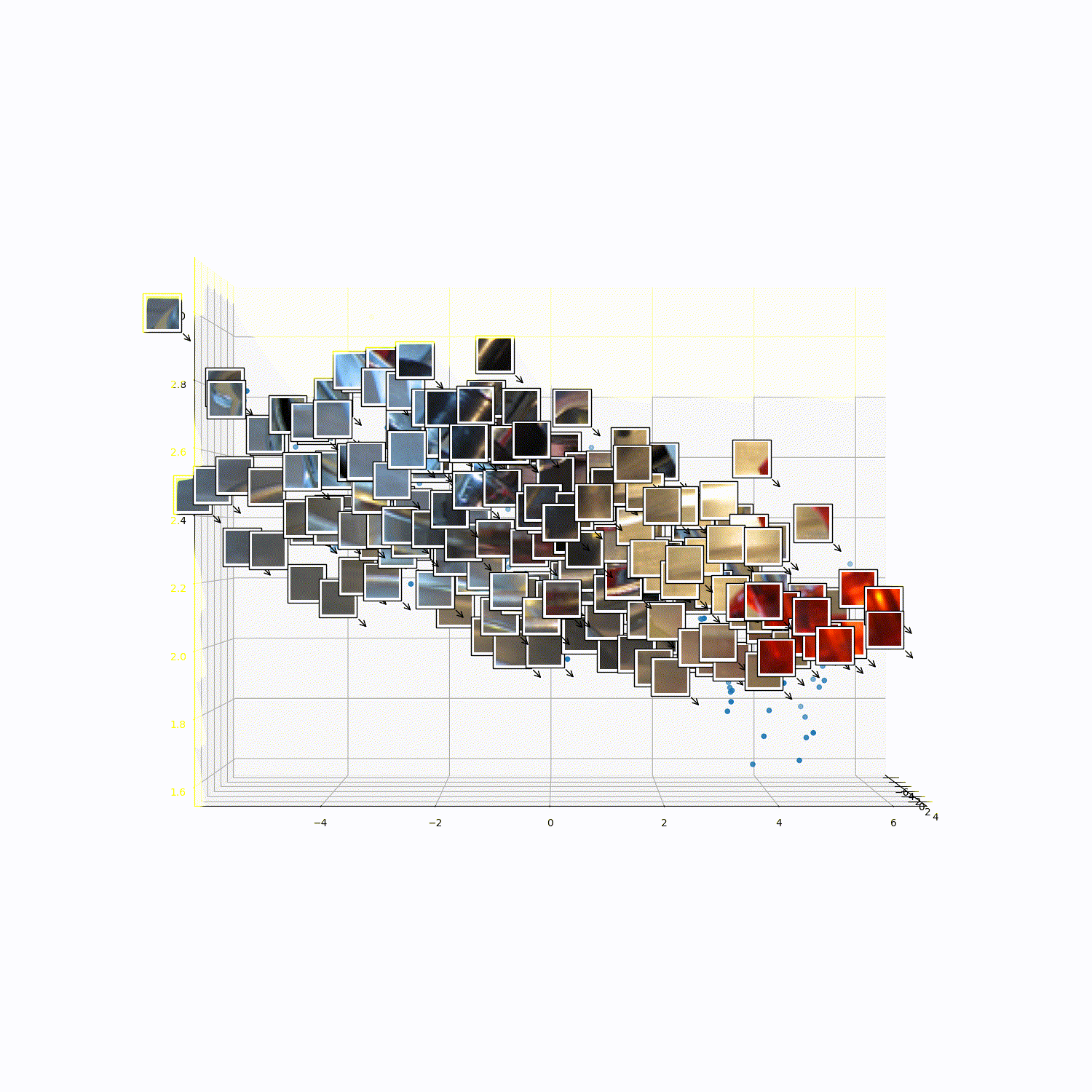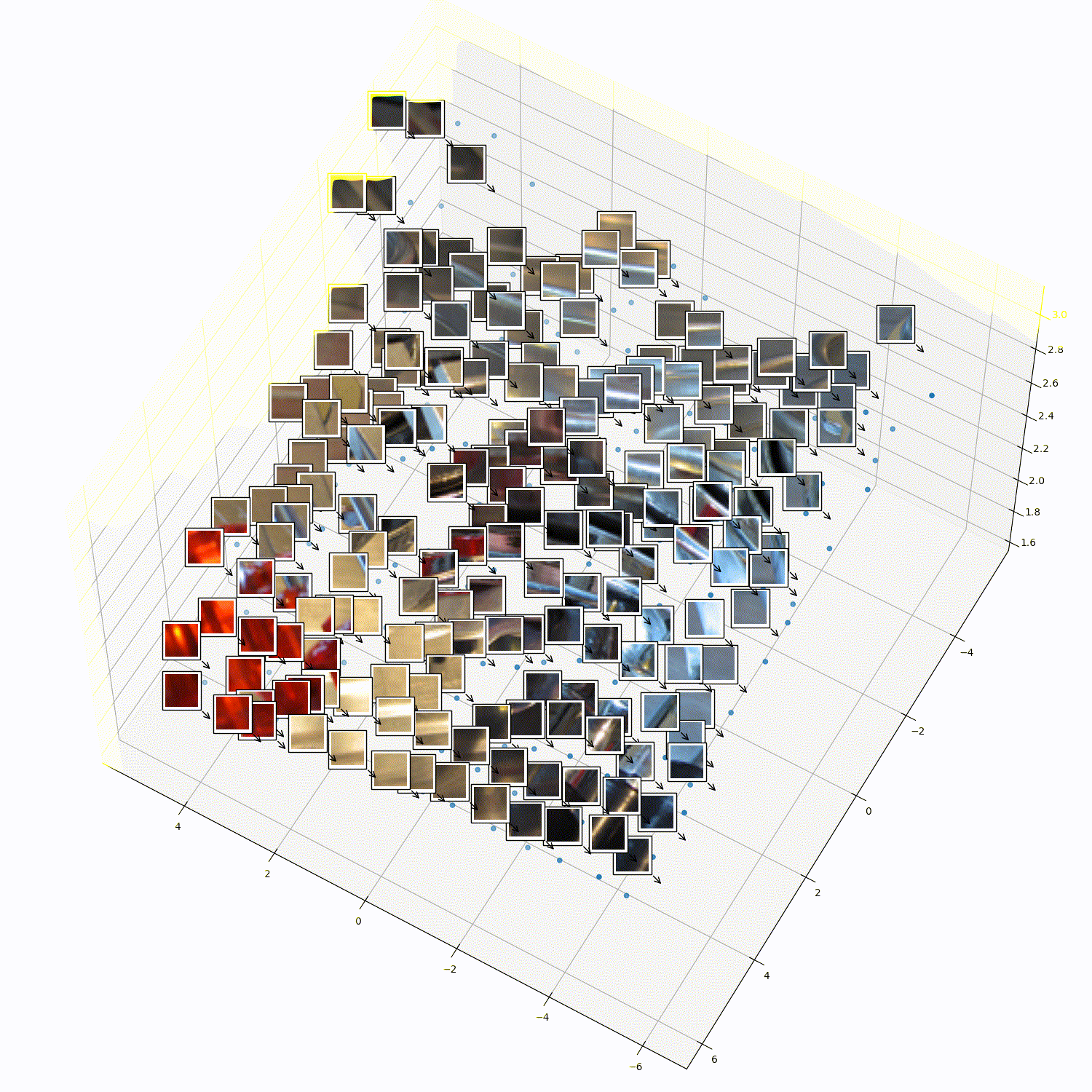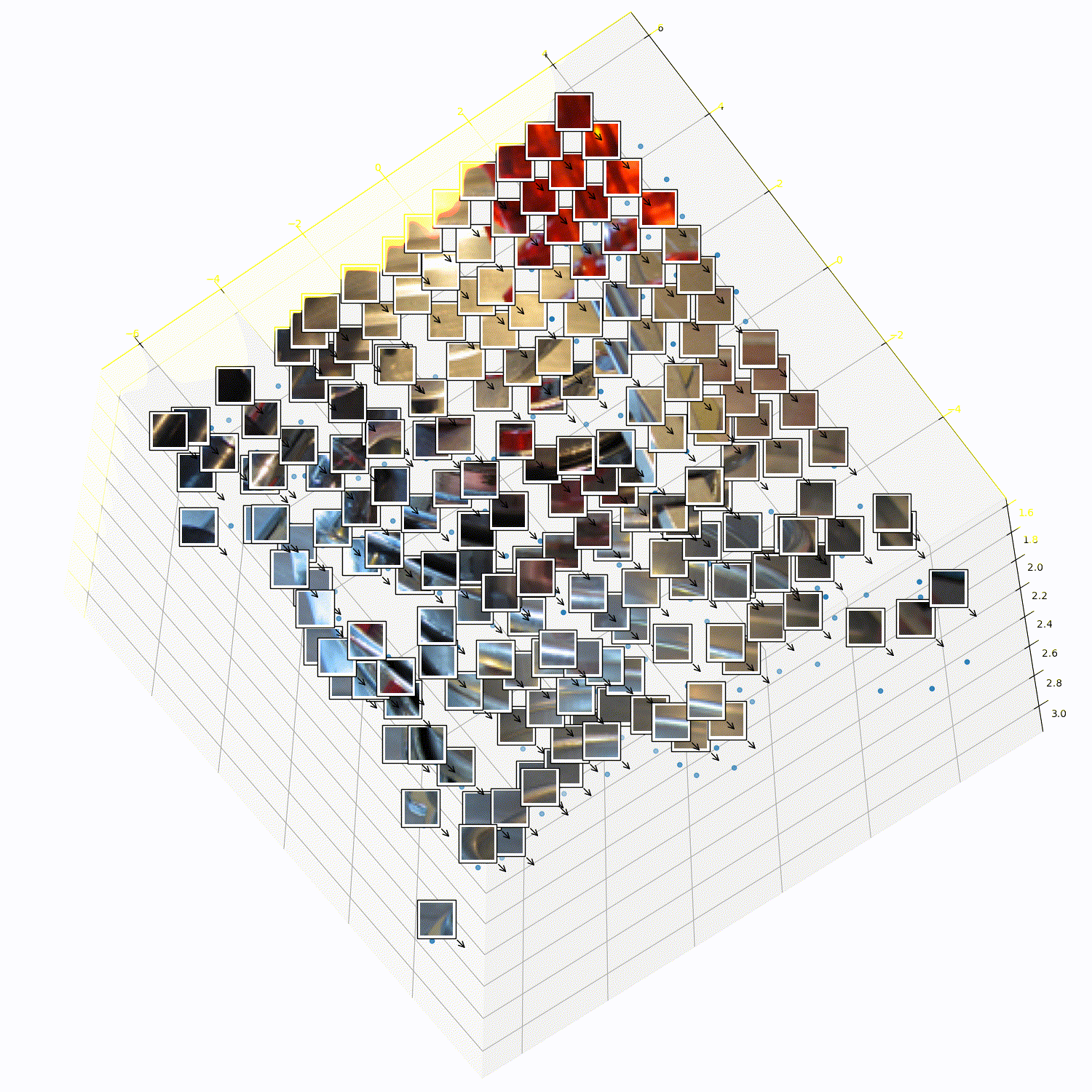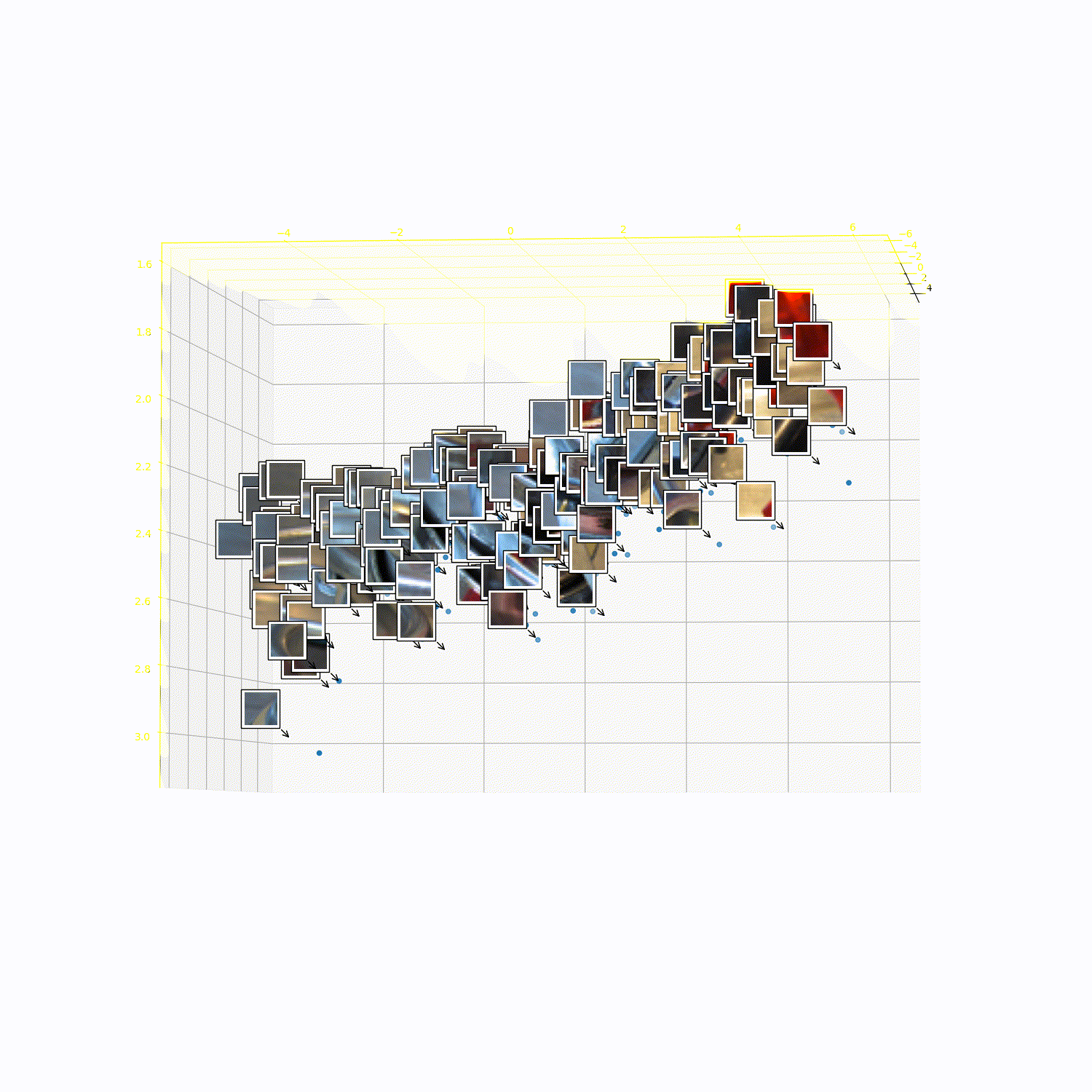
What does 3DTRL learn?
Recovering Tokens in 3D
Pseudo-Depth Estimation
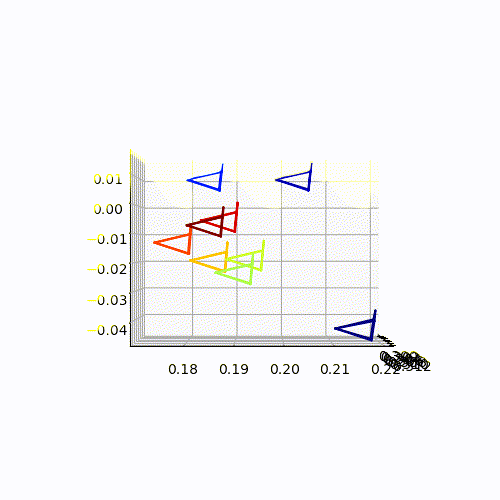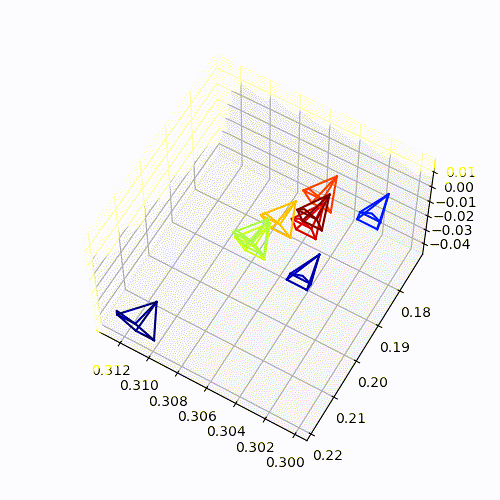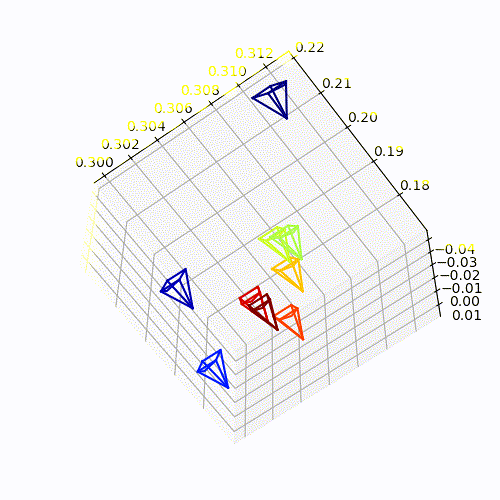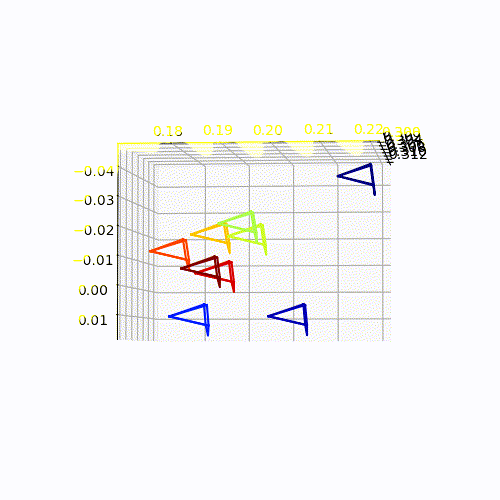
Camera-pose Estimation
What downstream tasks does 3DTRL benefit?
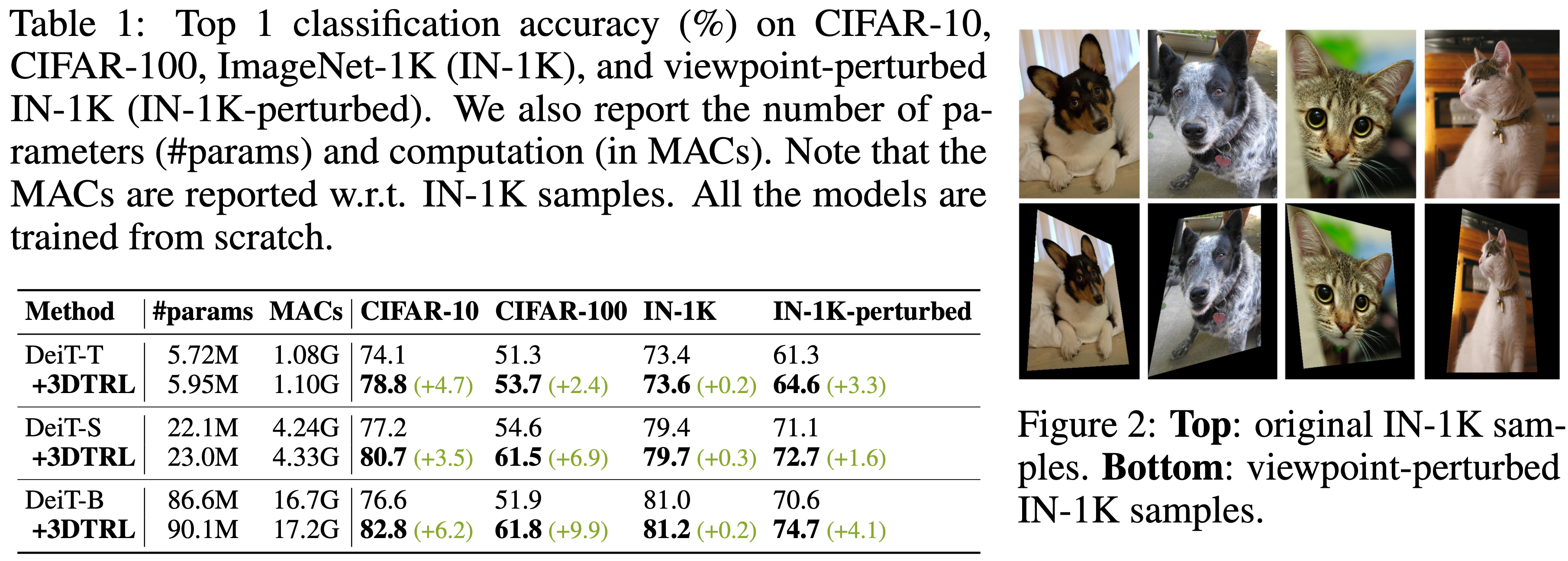
Image Classification
Images in standard datasets are natually taken from so many viewpoints. With 3DTRL, vision models better learn to classify and is more robust to viewpoint changes.
Multi-view Video Alignment
We can align videos from different viewpoints, even between egocentric (first-person) view and third-person views.
| Third-person view |
First-person view GT |
Ours |
DeiT+TCN |


Our full experimental results of video alignment, across five datasets.
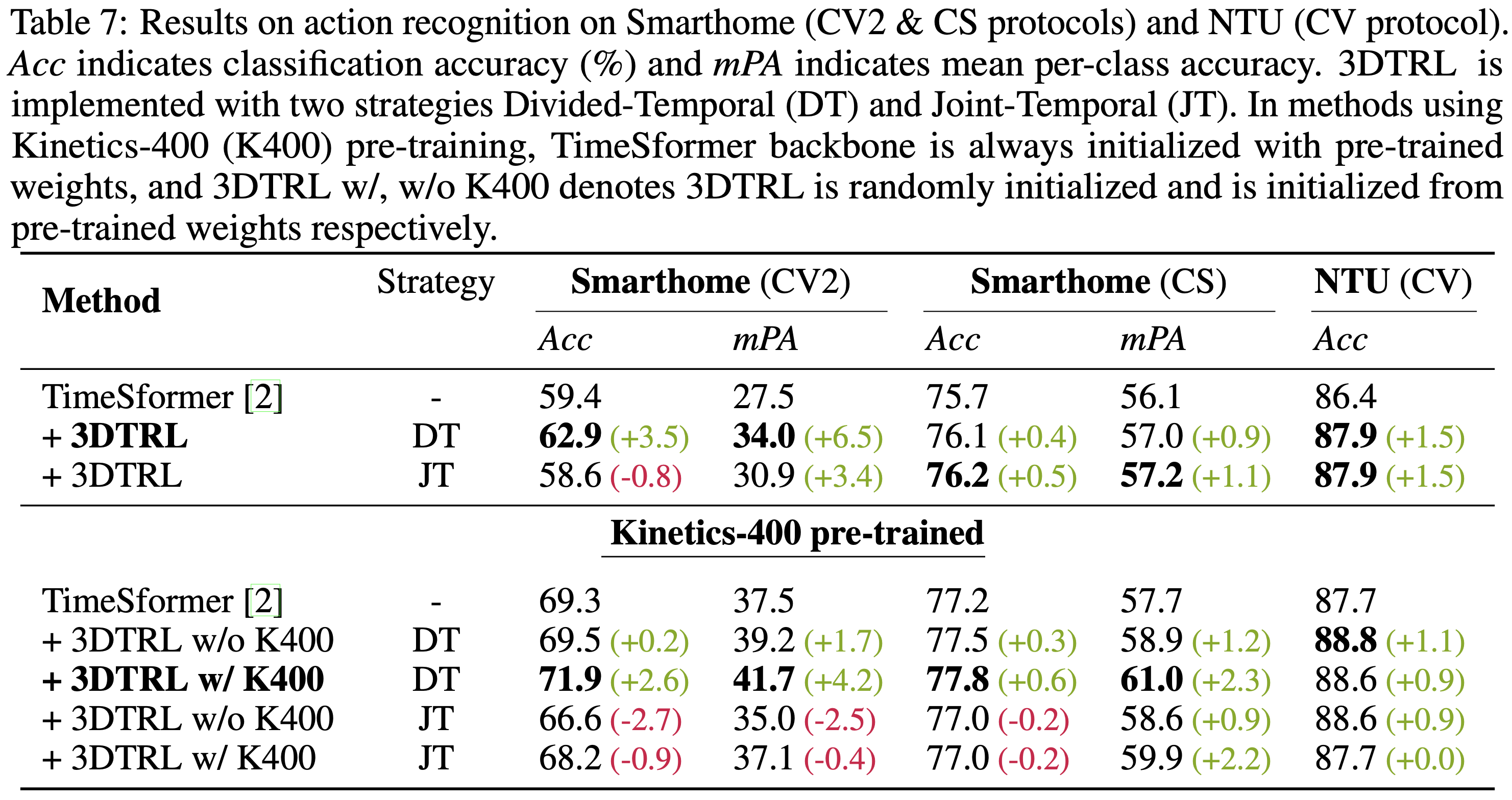
Action Recognition in Cross-View Videos
Robot Object Retrival Task
Given a target image, the robot is required to find the object in the scene starting from other viewpoints.
| Model |
Given Target |
Find |
Find |
Find |
| w/ 3DTRL |
 |
 |
 |
 |
| w/o 3DTRL |
|
 |
 |
 |